
RAG entreprise : 5 erreurs qui arrivent après le POC
Un RAG entreprise est rapide à prototyper. En faire un produit utile et stable est un gros challenge. Découvrez les 5 erreurs les plus courantes en production et comment les anticiper.
Un RAG (Retrieval-Augmented Generation) est une architecture qui permet à une IA de chercher dans vos sources internes avant de répondre : documents, bases de connaissances, procédures, contrats, parfois bases de données ou web. Si le sujet est nouveau pour vous, vous pouvez commencer par notre page de documentation Données et RAG.
Mettre en place un RAG d'entreprise donne souvent une impression trompeuse.
En quelques heures, vous pouvez obtenir une première démo convaincante. Vous prenez dix documents bien choisis, vous les faites passer dans un pipeline, et l'assistant répond déjà à des questions qui ressemblent à de vrais cas d'usage.
Imaginez une direction RH qui teste un assistant interne. On lui donne le règlement intérieur, la convention collective, trois procédures de congés, deux notes sur le télétravail et une FAQ. Un collaborateur demande : "Combien de jours de télétravail puis-je prendre par semaine ?" L'assistant retrouve le bon passage, synthétise la réponse, cite la source. Tout le monde sourit. Le POC est validé.
Puis arrive la production.
Il ne s'agit plus de répondre à dix questions sur dix documents propres. Il faut absorber des milliers de fichiers, plusieurs versions contradictoires, des droits d'accès, des noms de produits, des références clients, des tableaux, des documents scannés, du jargon interne, et des utilisateurs pressés qui formulent rarement leurs demandes comme dans une démo.
Rien d'étonnant à ce que 95% des projets IA échouent en entreprise.
Voici cinq erreurs que nous constatons régulièrement chez nos clients.
Erreur n°1 : prendre le POC pour la réalité
Le premier piège du RAG, c'est sa facilité apparente.
Pour une démo, le chemin est court : choisir un petit corpus, convertir les fichiers, découper le texte, calculer les embeddings, rechercher les extraits pertinents, puis générer une réponse.
Cette chaîne fonctionne vite si les documents sont propres et le sujet bien cadré. Mais un système de production ne travaille pas dans un décor préparé.
Dans une entreprise, les documents sont rarement homogènes. Vous avez des PDF exportés depuis Word, des présentations, des tableaux Excel, des captures d'écran, des tickets, des contrats, des comptes rendus et souvent des fichiers dont personne ne connaît vraiment l'origine.
Le problème n'est pas seulement le volume. C'est la diversité, le statut des documents, et les incohérences entre sources. Une procédure de 2023 peut être techniquement pertinente mais remplacée par une note de 2026. Un contrat client peut contenir une exception qui contredit la règle générale. Une slide commerciale peut simplifier un produit que la documentation technique décrit autrement.
Il faut aussi "éduquer" l'IA au vocabulaire de l'entreprise : acronymes internes, surnoms de produits, noms de projets, abréviations métier, anciennes appellations encore utilisées par les équipes. Sans ce travail, l'assistant peut chercher au mauvais endroit ou rater une information pourtant présente.
La connaissance d'entreprise n'est pas un tas de fichiers. C'est un ensemble de sources, de versions, de droits, de priorités et de vocabulaire partagé.
Pour passer en production, il faut donc décider quelle version fait autorité, quels fichiers ignorer, quels droits appliquer, comment gérer les contradictions et comment citer les sources. Ces sujets paraissent administratifs. En réalité, ils conditionnent la confiance.
Erreur n°2 : dépendre d'un seul fournisseur d'IA
Une entreprise attend d'un outil interne qu'il soit disponible, rapide et stable. Dans beaucoup de contextes, la référence implicite est celle des applications SaaS matures : 99,99 % de disponibilité, des temps de réponse prévisibles, peu d'interruptions visibles.
Avec les modèles d'IA, cette attente se heurte à une réalité plus rude. Les fournisseurs d'IA sont puissants, mais ils ne se comportent pas toujours comme des briques d'infrastructure classiques. Les latences varient, certaines requêtes échouent, des modèles deviennent temporairement indisponibles, les performances changent selon la charge, les régions ou les mises à jour internes.
Chez ATG, nous mesurons de façon permanente la vitesse de réponses des API de nombreux fournisseurs d'IA. Le benchmark ci-dessous compare le taux de succès de plusieurs fournisseurs sur des tâches de génération de texte.
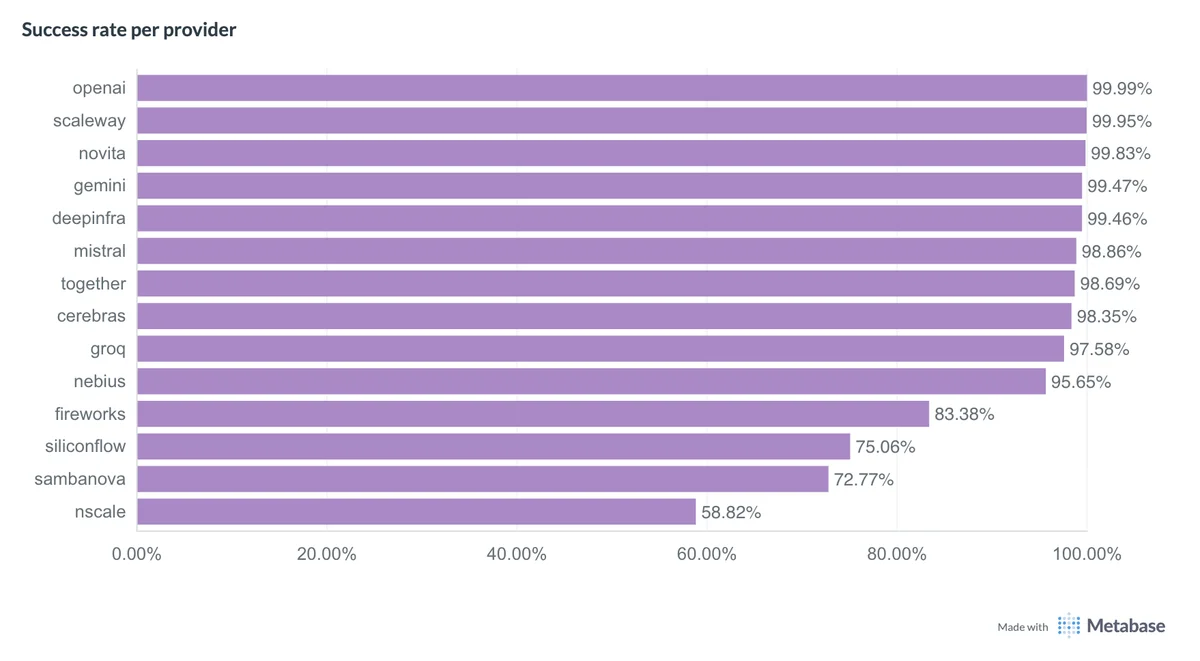 Benchmark ATG Q1 2026 des taux de succès des fournisseurs de génération de texte
Benchmark ATG Q1 2026 des taux de succès des fournisseurs de génération de texte
Attention : ce graphe ne mesure que le taux de succès. Il ne dit rien de la latence. Un fournisseur peut afficher un excellent taux de réussite, mais répondre trop lentement pour une bonne expérience utilisateur (c'est le cas pour OpenAI notamment).
La conclusion est simple : si votre RAG dépend d'un seul fournisseur d'IA et d'un seul modèle, toute l'expérience utilisateur dépend de cette brique.
La bonne approche consiste plutôt à concevoir une architecture capable de changer de route :
- plusieurs fournisseurs d'IA pour un même type de tâche ;
- plusieurs modèles selon la complexité de la question ;
- des mécanismes de fallback quand une requête échoue ;
- du monitoring sur la latence, les erreurs et la qualité ;
- une sélection dynamique du modèle le plus adapté.
Erreur n°3 : croire qu'il suffit de déployer son propre modèle d'IA
La solution paraît alors simple : il suffit de déployer son propre modèle d'IA.
Sur le papier, l'idée est séduisante. Vous réduisez la dépendance externe, vous maîtrisez l'infrastructure, vous contrôlez mieux vos données. Et si le RAG fournit les bons extraits, le modèle n'a plus qu'à rédiger la réponse, non ?
Pas vraiment.
Les requêtes réelles sont rarement propres. Un utilisateur ne demande pas :
Quelle est la procédure de validation des congés payés ?
Il demande plutôt :
euh pour Sophie du support elle veut poser 3j juste avant le rush, elle a deja pas mal abusé ce trimestre non ? on peut refuser ou faut tourner ça cmt?
Le système doit comprendre la demande, retrouver les bons textes, distinguer règle générale et cas particulier, éviter de valider un biais managérial, puis proposer une formulation exploitable.
La recherche apporte les sources. Le modèle doit encore raisonner.
Le local peut avoir du sens pour des cas cadrés : extraction simple, reformulation, classification, RAG factuel sur un domaine étroit. Mais dès que l'assistant doit traiter des questions métier ambiguës, croiser plusieurs sources ou utiliser des outils, les modèles plus puissants redeviennent difficiles à éviter.
Nous avons détaillé ce sujet dans notre article sur les LLM en local. Le point clé est simple : faire tourner un modèle robuste avec de bonnes performances coûte cher, surtout avec plusieurs utilisateurs simultanés.
La bonne stratégie n'est donc pas de choisir une fois pour toutes entre cloud, local, petit modèle ou grand modèle. C'est d'orienter intelligemment les requêtes : modèle léger pour les tâches simples, modèle plus puissant pour les raisonnements complexes, modèle spécialisé pour les embeddings ou la vision, fournisseur alternatif si le premier est lent.
Erreur n°4 : faire uniquement de la recherche vectorielle
Beaucoup de projets RAG commencent avec une recherche vectorielle pure. C'est logique : les embeddings sont au cœur du RAG moderne, et la recherche sémantique est impressionnante.
Elle permet de retrouver un passage même si l'utilisateur n'emploie pas les mêmes mots que le document. "Politique de télétravail" peut retrouver "modalités de travail à distance". "Comment déclarer une absence ?" peut retrouver "procédure d'absence maladie".
Mais l'entreprise manipule énormément d'informations qui n'ont pas de sens sémantique universel.
Un nom de client, une référence produit, un code projet, un identifiant contrat, un acronyme interne ou le nom d'un collaborateur ne "signifie" pas grand-chose pour un embedding. ACME-0427, Projet Atlas, PRD-19-B, Jean Martin ou Pack Horizon sont des clés. Pas des concepts.
Si votre RAG repose uniquement sur la proximité sémantique, il risque de manquer précisément les informations que les utilisateurs cherchent.
C'est pour cela qu'un bon RAG combine (au moins) recherche sémantique, recherche par mots-clés, métadonnées et priorisation des sources en fonction de leur fiabilité.
Le RAG doit aussi apprendre à arbitrer entre documents contradictoires : date, propriétaire, statut, périmètre, source officielle, exception contractuelle. Sinon, il ne répond pas à partir de "la connaissance de l'entreprise". Il répond à partir d'un tas de fichiers.
Un bon RAG ne trouve pas seulement un passage proche. Il trouve le bon passage, dans le bon document, avec le bon niveau d'autorité.
Erreur n°5 : croire que les utilisateurs veulent seulement chercher
Le dernier piège est souvent découvert trop tard : les utilisateurs ne veulent pas seulement chercher.
Au début, ils sont impressionnés par un assistant capable de répondre à partir des documents internes. Puis, très vite, ils demandent autre chose :
- "Peux-tu me rédiger une note de synthèse au format Word ?"
- "Va vérifier si cette information est toujours vraie sur Internet."
- "Compare cette procédure avec le contrat du client."
- "Envoie-moi la synthèse par e-mail"
- "Cherche dans le CRM."
- "Fais-moi un tableau exploitable."
Autrement dit, ils ne perçoivent pas l'outil comme un simple RAG. Ils le perçoivent comme une interface de travail.
Si votre solution ne sait faire que de la recherche documentaire, elle atteindra vite son plafond d'usage. C'est là que les architectures agentiques, les outils (recherche web, génération de documents, etc.) et des protocoles comme MCP deviennent importants.
Mais ajouter des outils ne suffit pas. Il faut aussi une interface fluide, intégrée aux usages existants quand c'est possible, et suffisamment claire pour que l'utilisateur comprenne ce que l'assistant sait faire.
Enfin, il faut mesurer. Un système RAG ne se valide pas avec cinq questions en comité projet. Il se valide avec des centaines, puis des milliers de questions représentatives : simples, ambiguës, hors périmètre, avec noms propres, sur documents anciens, avec sources contradictoires, ou nécessitant un outil.
Il faut générer des questions réalistes, analyser les feedbacks utilisateurs, suivre les échecs, analyser les sources citées, mesurer les temps de réponse et rejouer des jeux de tests après chaque changement.
Si vous ne devez retenir qu'une chose
Un RAG est facile à lancer, mais difficile à industrialiser.
La démo montre le potentiel. La production révèle les contraintes : gouvernance documentaire, jargon métier, incohérences entre sources, disponibilité des fournisseurs d'IA, routage des modèles, recherche hybride, outils, interface et mesure de la qualité.
L'approche Ask This Guy
Chez Ask This Guy, nous abordons le RAG comme une brique de production, pas comme une simple recherche vectorielle.
Nous connectons les sources documentaires de l'entreprise, adaptons le traitement aux formats réels, combinons recherche sémantique, mots-clés, métadonnées et reranking, utilisons plusieurs modèles et fournisseurs d'IA selon les besoins, intégrons des outils ou serveurs MCP quand le cas d'usage le justifie, et mesurons les performances comme les feedbacks utilisateurs.
Le but n'est pas de promettre un assistant magique. Le but est de construire un système fiable, explicable et utile, capable de progresser avec vos usages.
Si vous préparez un RAG entreprise, commencez par la bonne question : non pas "peut-on faire une démo ?", mais "qu'est-ce qui devra tenir quand 500 utilisateurs poseront de vraies questions sur de vraies données ?"
Réservez une démo pour voir comment Ask This Guy peut vous aider à passer du RAG prometteur au RAG réellement utilisable en entreprise.

.webp)
