Cette page est une traduction automatique. Pour les informations de référence, consultez la version anglaise.
Documents et images
Comment ATG traite les documents et images : pipeline multimodal, extraction de texte, langues supportées et recommandations de mise en forme pour de meilleurs résultats IA.
L'assistant IA This Guy met en œuvre un pipeline de traitement documentaire multimodal qui transforme des documents complexes en bases de connaissances indexées intelligemment. Le système atteint plus de 95 % de précision en extraction de texte et supporte plus de 50 langues avec détection automatique.
Un des points forts de This Guy est de gérer intelligemment les images dans les documents et de pouvoir les réutiliser dans ses réponses. Voici comment fonctionne le pipeline :
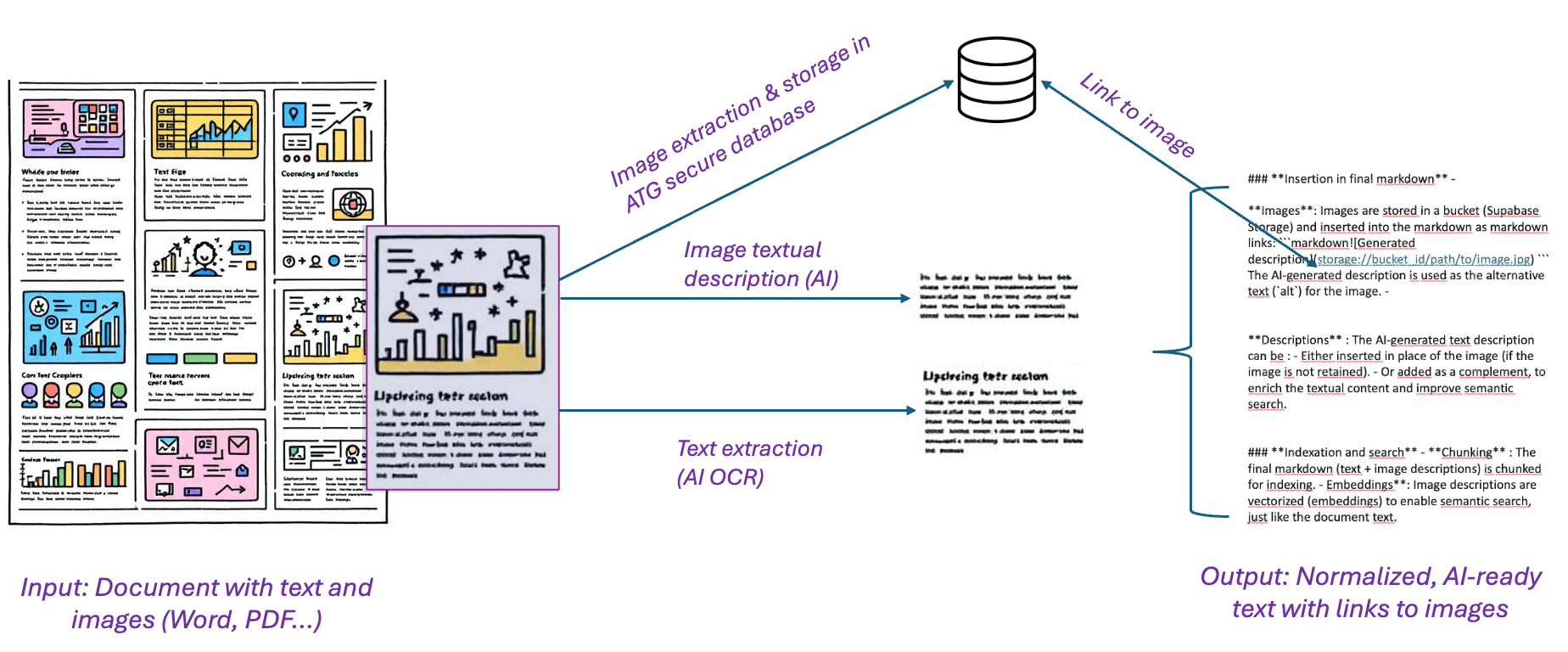 Pipeline de traitement et d'intégration des images dans ATG
Pipeline de traitement et d'intégration des images dans ATG
Pipeline de traitement et d'intégration des images dans ATG
Recommandations pour la mise en forme de vos documents
Pour optimiser le travail et la précision de This Guy, il est essentiel de rendre vos (futurs) documents aussi explicites que possible. Voici des conseils pour que vos équipes structurent leurs documents afin qu'ils soient plus facilement interprétables par des outils IA comme Mistral ou autres :
Clarté et précision : Assurez-vous que le contenu est clair et précis. Évitez les ambiguïtés et soyez aussi détaillés que possible.
Structure cohérente : Gardez une structure cohérente entre informations textuelles et visuelles. Utilisez des titres et sous-titres pour organiser le contenu et faciliter la compréhension.
Séparation des éléments : Distinguez clairement les types d'information (par ex. séparer les paragraphes des images ou graphiques).
Mots-clés : Intégrez des mots-clés pertinents pour identifier le contenu et le contexte.
Formatage uniforme : Utilisez un formatage uniforme pour les éléments similaires (ex. toutes les images formatées de la même façon).
Annotations et légendes : Ajoutez des annotations et légendes aux images et graphiques pour donner du contexte et clarifier le contenu.
Vue d'ensemble de l'architecture du pipeline
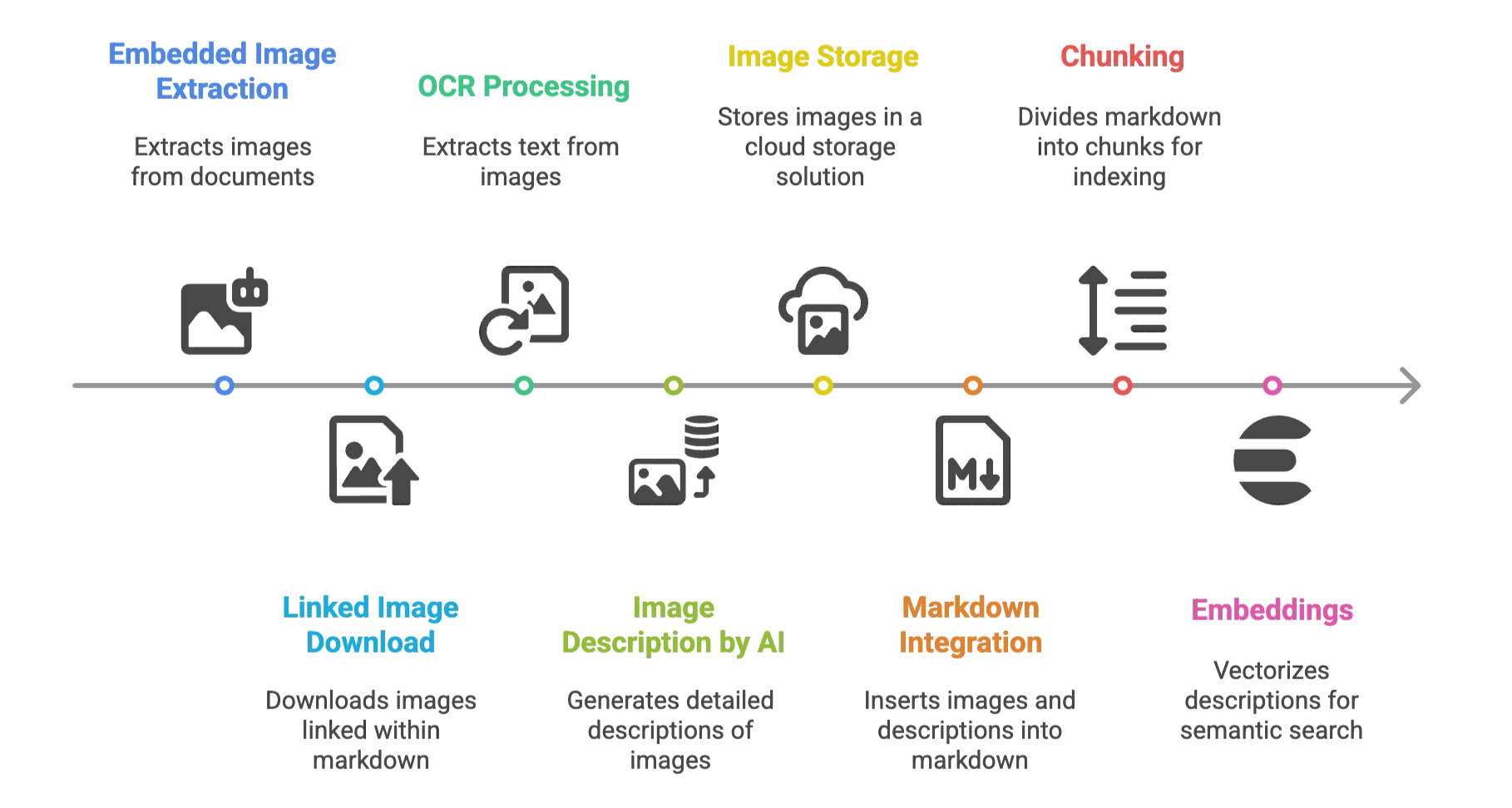 Intégration du pipeline de traitement des images ATG
Intégration du pipeline de traitement des images ATG
Intégration du pipeline de traitement des images ATG
Le système d'intégration documentaire ATG fonctionne via un pipeline en cinq étapes, du téléversement initial jusqu'à l'indexation dans la base de connaissances. Cette architecture respecte des standards entreprise pour la scalabilité et la fiabilité.
Étape 1 : Ingestion des documents
Le système accepte plusieurs formats (PDF, Word, PowerPoint, etc.). Les documents sont validés et mis en file pour le traitement, avec détection automatique du format et extraction des métadonnées.
Étape 2 : Extraction et séparation du contenu
Le pipeline sépare le contenu textuel des images intégrées en préservant la structure du document et en préparant les assets pour des flux de traitement dédiés.
Étape 3 : Couche de traitement IA
Cette étape met en œuvre une analyse multimodale parallèle avec des technologies de vision par ordinateur et de traitement du langage naturel. Texte et images sont traités simultanément pour une efficacité maximale.
Flux texte :
- OCR avancé pour les documents scannés et le texte intégré
- Détection de langue et normalisation du texte
- Analyse sémantique et extraction d'entités
Flux images :
- Analyse du contenu visuel et génération de descriptions
- Reconnaissance de graphiques, schémas et tableaux
- Compréhension contextuelle des images avec logique métier
Étape 4 : Intégration et enrichissement du contenu
Le système combine le texte traité et les descriptions d'images en format markdown structuré, pour une représentation unifiée qui préserve l'information visuelle et textuelle.
Génération du markdown :
- Les images sont stockées de façon sécurisée dans le stockage cloud ATG
- Les descriptions générées par l'IA servent de texte alternatif pour l'accessibilité
- Préservation de la structure hiérarchique (titres, formatage)
- Renvois entre images et contenu textuel associé
Étape 5 : Indexation et recherche dans la base de connaissances
La dernière étape met en œuvre vectorisation et embeddings pour permettre la recherche sémantique.
Fonctionnalités d'indexation :
- Stratégie de chunking : les documents sont segmentés en chunks logiques pour une récupération optimale
- Embeddings vectoriels : le texte et les descriptions d'images sont convertis en vecteurs de haute dimension
- Recherche hybride : combinaison de recherche par mots-clés et sémantique
- Mises à jour en temps réel : ré-indexation automatique lorsque les documents sont modifiés
Stack technique
Le système ATG s'appuie sur des technologies IA de pointe tout en conservant flexibilité et souveraineté des données (selon la politique IA choisie par les administrateurs) :
Traitement OCR
- OCR : reconnaissance de texte à plus de 95 % de précision sur les documents standards
- Multilingue : détection automatique de plus de 50 langues
- Reconnaissance de l'écriture manuscrite : capacités avancées pour les manuscrits
IA vision multimodale
- Compréhension multimodale niveau entreprise pour une analyse documentaire complète
- Descriptions contextuelles : analyse détaillée des images avec intégration du contexte métier
- Reconnaissance de schémas techniques : traitement dédié aux graphiques, courbes et illustrations techniques
Solutions IA européennes
- Hébergement conforme UE pour la souveraineté des données
- Inclusion, le cas échéant, de modèles open-weight dans les flux de traitement
- Traitement multimodal efficace avec résidence des données en Europe
Enrichissement linguistique
- Enrichissement et analyse sémantique avancés du texte
- Amélioration automatique de la structure et de la lisibilité des documents